
Fraud in Medical Research: Understanding the Carlisle Approach
/For the video version, click here.
A paper was recently published that some have described as nothing short of a "bombshell" calling into question whether multiple studies in some of our most prestigious medical journals are actual frauds. And, impressively, doing it all with a relatively simple statistical approach. The question is – do the accusations by Dr. J. B. Carlisle, appearing here in the journal Anaesthesia, hold up to close scrutiny?

The "B" stands for Ballsy.
What Carlisle has come up with is a metric that can be applied to any randomized trial – a single number that might tell you that the data is too suspicious to be believed. But in order to understand the metric, you need to know a few things about randomized trials.
Randomized trials take some population of individuals and then randomize them into two or more groups. Sometimes it is a drug versus a placebo, sometimes a drug vs. a drug, or there could be multiple arms and interventions. The key isn't what is being tested. The key is the word "random".
The magic of randomized trials is that the act of randomization tends to balance baseline variables between the groups. If you want to see how a new cholesterol medication works, you don't want to give all the elderly people the drug and all the young people placebo, you want balance.
There are a variety of ways to randomize, but the hope is that, in the end, the magic of random numbers will do its thing.
And it usually does.
We typically see the effect of randomization in "Table 1" of a medical study. Here's table 1 from my favorite randomized trial:
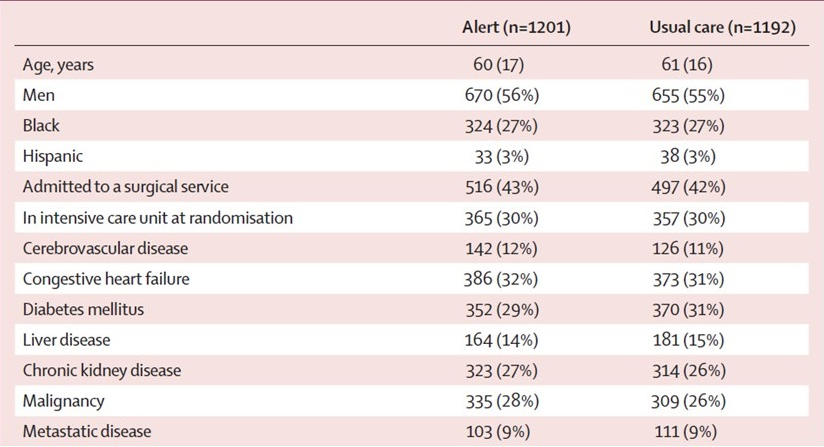
Wilson et. al. The "et al" stands for shameless self-promotion.
This was a randomized trial I ran looking at electronic alerting for acute kidney injury. And you'll have to take my word that it is not fraudulent. I mean, if I had wanted to fake the data I probably would have made the study positive – but that's neither here nor there. Basically, if you look across the two arms, you can see that the numbers look pretty similar for all of these baseline variables. 56% were men in the alert arm, compared to 55% in the usual care arm. Nothing too suspicious, right?
It turns out that we have a way to quantify weirdness of any data we look at. That quantification is called the p-value and in the case here it can be interpreted as how unlikely the observed data is assuming that allocation to one or the other treatment arm was totally random.
I've put p-values next to each of the measurements in that table. Take a look:
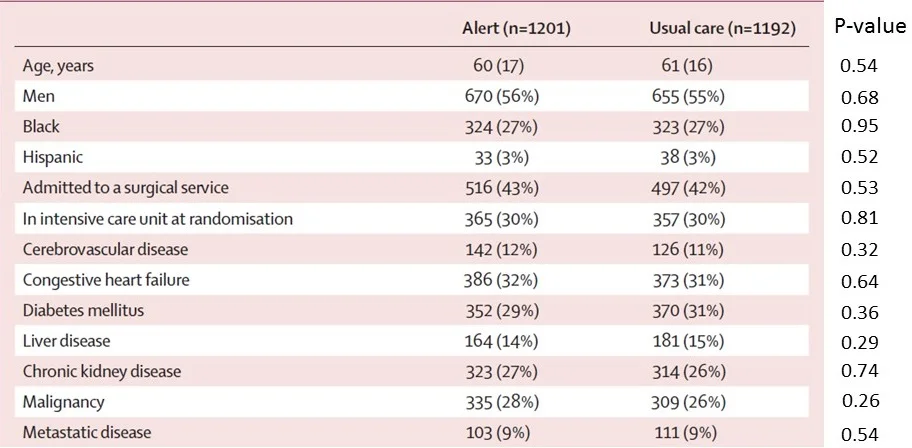
Unfortunately, blog posts don't count as citations.
So for the first line there, that p-value of 0.54 means that we'd expect to see results as strange as these, or more strange, 54% of the time assuming that the treatment allocation was truly random. In other words, the fact that the mean age was technically higher in the usual care group isn't particularly alarming.
But you'll note that there are p-values all down the line – and they bounce around a bit. Here they range from a low of 0.29 to a high of 0.95.
In fact, under true random conditions, the p-value distribution is uniform. People often think that if the study is randomized, the p-values should hover somewhere around 0.5. This isn’t right. Here I've simulated 1000 variables in a truly randomized study and I'm showing the distribution of the p-values corresponding to those variables:
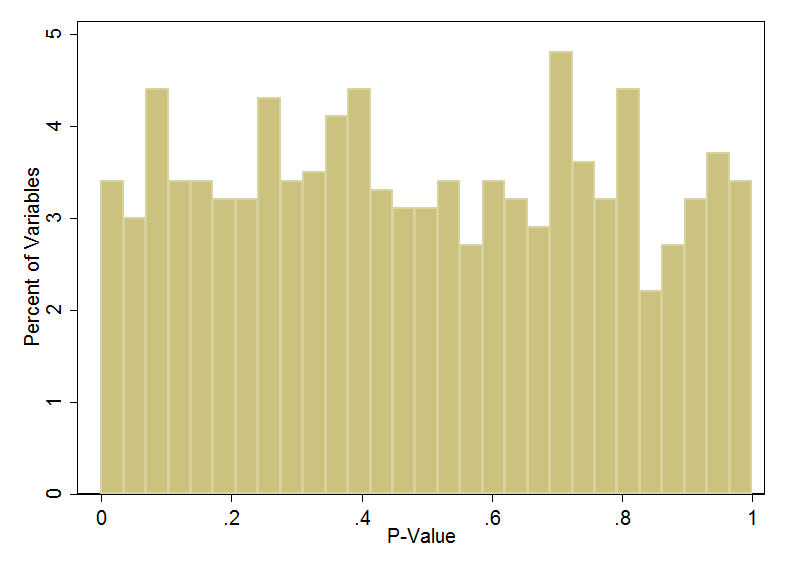
The uniform distribution. Rarely seen in medicine. In fact, does anyone have an example that isn't the p-value?
See – nice and uniform, well with a little randomness because random is never perfect. But roughly speaking, 5% of p-values are below 0.05 and 5% of the p-values are above 0.95.
Ok, onto Carlisle's paper.
He looked at 5,087 randomized trials and looked at each variable that compared baseline factors between the randomized groups. That left a total of just under 30,000 variables to look at. He calculated the p-value for each one of those variables using a standard statistical test, just like I did in my own trial above.
By the way, can I just say what a herculean task this was. I mean, he is pouring through these journals, manually extracting tens of thousands of data points. I can only hope it was a labor of love.
Now comes the tricky part. Every trial has multiple baseline variables measured. How do you aggregate the weirdness of all of those variables into a single number that is suggestive of overall trial weirdness? Do you average all the p-values? Take the lowest?
Carlisle used something called Stouffer’s method, which, like a fine stuffing, is used to combine the p-values of multiple studies in a meta-analysis.
Let's look at my study again (I promise - last time).
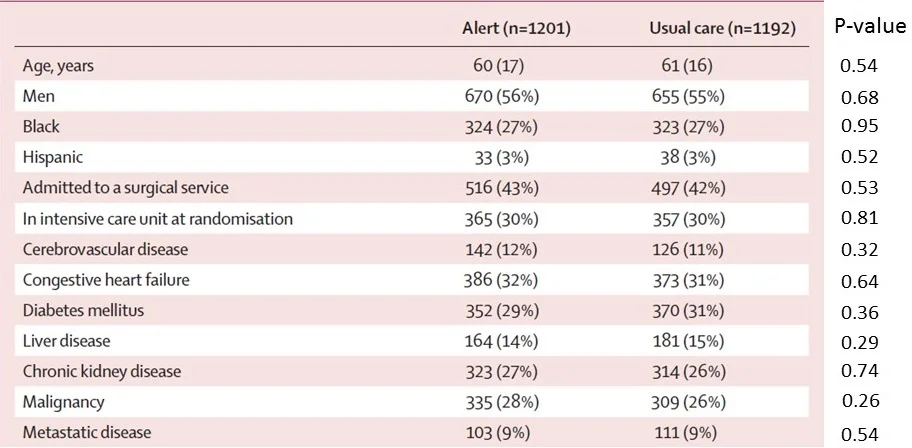
Using Stouffer's method, my "study p-value" is 0.52 – smack in the middle of the road. Nothing to see here.
To visualize how this works more clearly, you need to realize that a trial with 10 measured baseline factors, all with a p-value of, say 0.1, is really unlikely. As is a trial with 10 measured baseline factors, all with p-values of 0.9. This graph – simulating 10,000 studies, each with 10 baseline factors measured - illustrates it more clearly, I think:
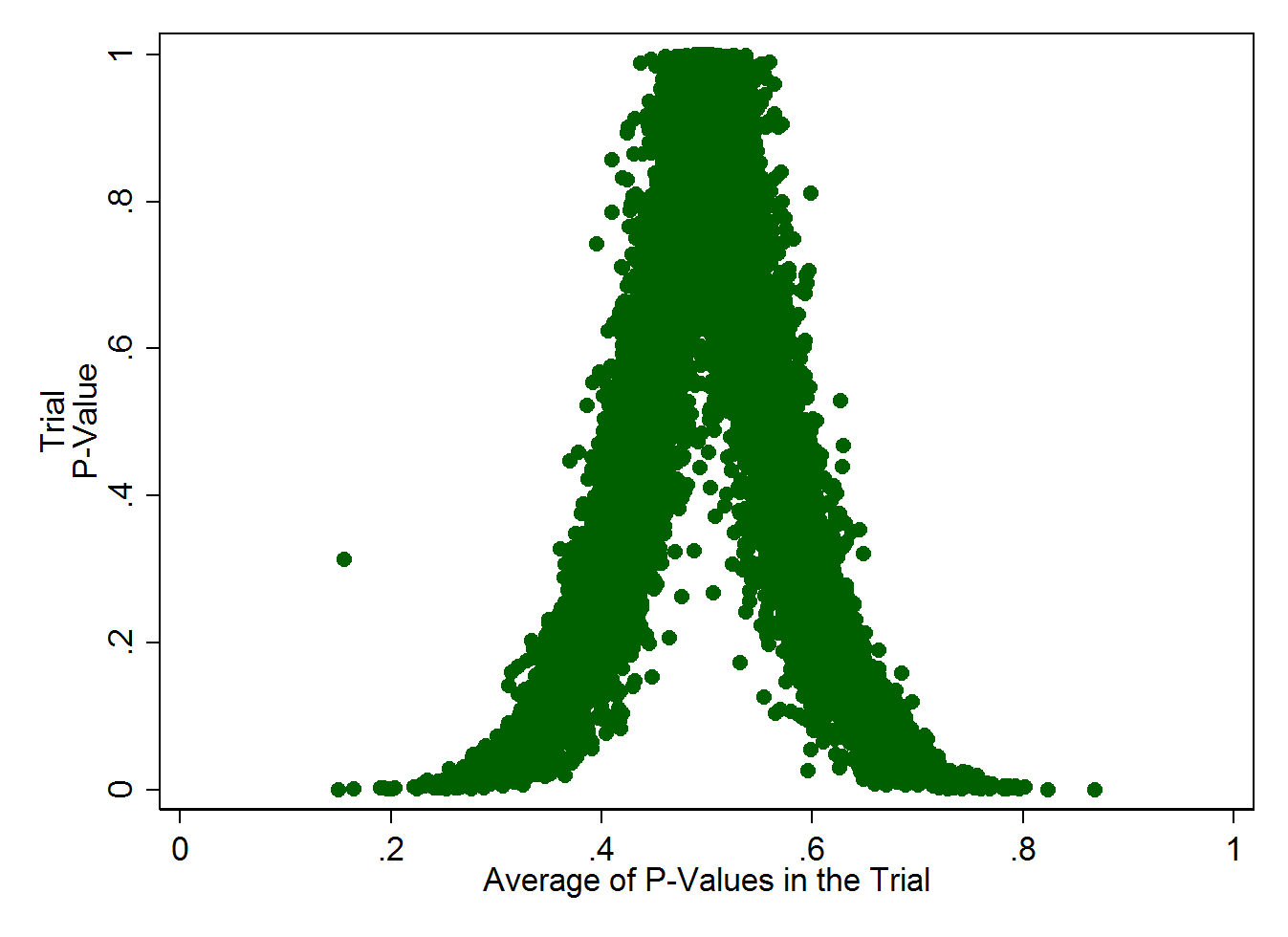
You can find the code I used to generate this here (Stata version).
What you see here is that the average of all the p-values within a single trial should be around 0.5. If the average of p-values starts to deviate too far from that, the overall trial P-value gets very low, very quickly. In fact, if a trial measured ten baseline factors, all of which had a somewhat reasonable p-value of 0.2, the overall trial P would be 0.001 or 0.1%. Pretty darn unlikely.
It's that overall p-value that Carlisle is using to flag trials as potentially fraudulent.
Let's look at the distribution of p-values across these 5,087 trials:
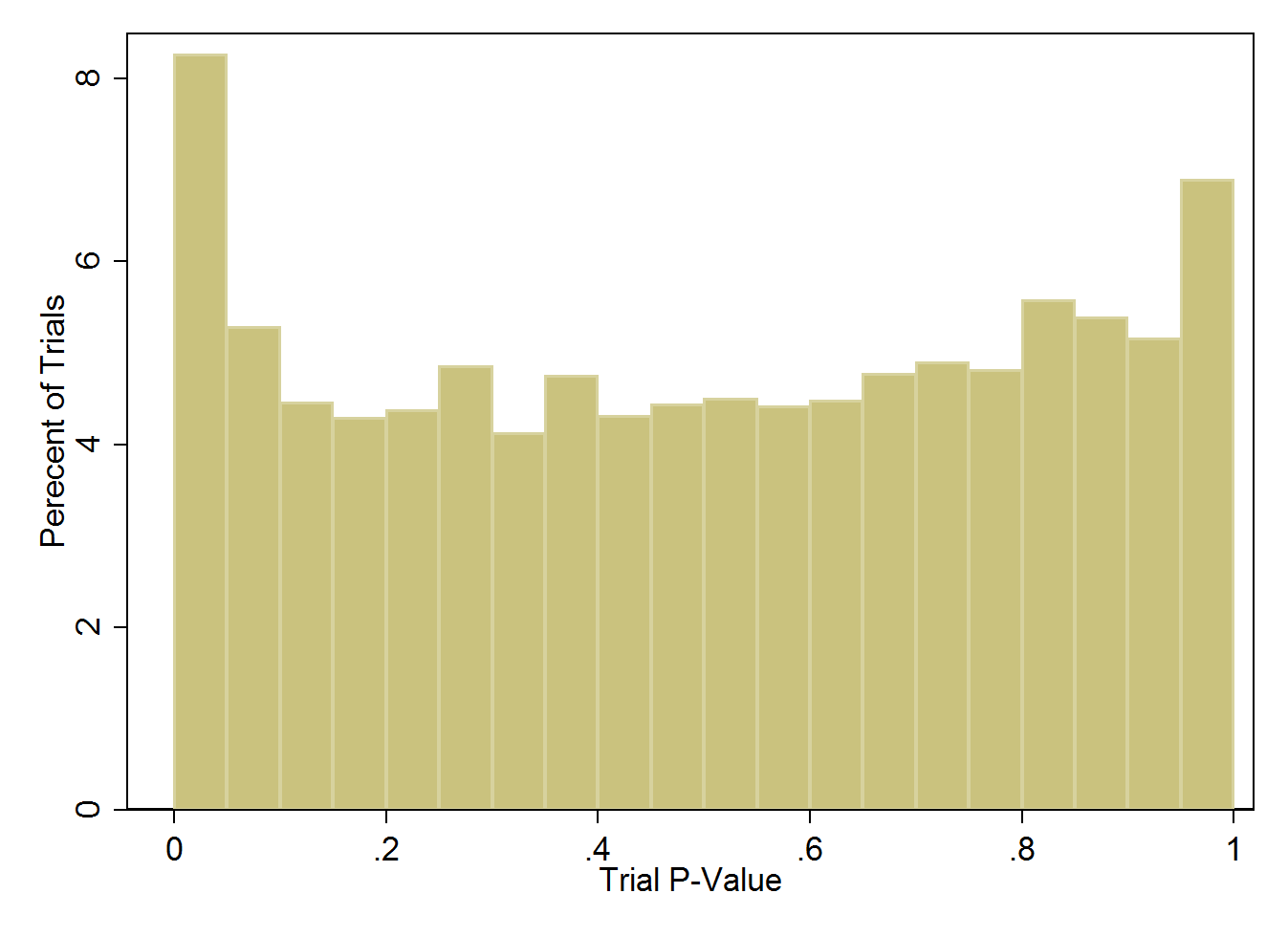
Distribution of trial p-values across more than 5000 studies.
What this should look like is a nice, uniform distribution – flat all the way across. What you see is a bit of an uptick at either end of the spectrum. On the left, an excess of trials with low trial p-values indicating lack of balance in the groups, and on the right an excess of trials with high trial p-values, indicating too much balance between the purportedly randomized groups. But keep in mind that the vast majority of trials here look just fine.
What does this mean? Let's start with the nefarious interpretation.
Clinical trialists, motivated by greed, or desire for recognition, or to get the next grant, or by their Big Pharma string-pullers, cook the data.
There is some evidence for this. Using Carlisle's method on trials that were subsequently retracted shows that many of them have these suspiciously balanced intervention groups.
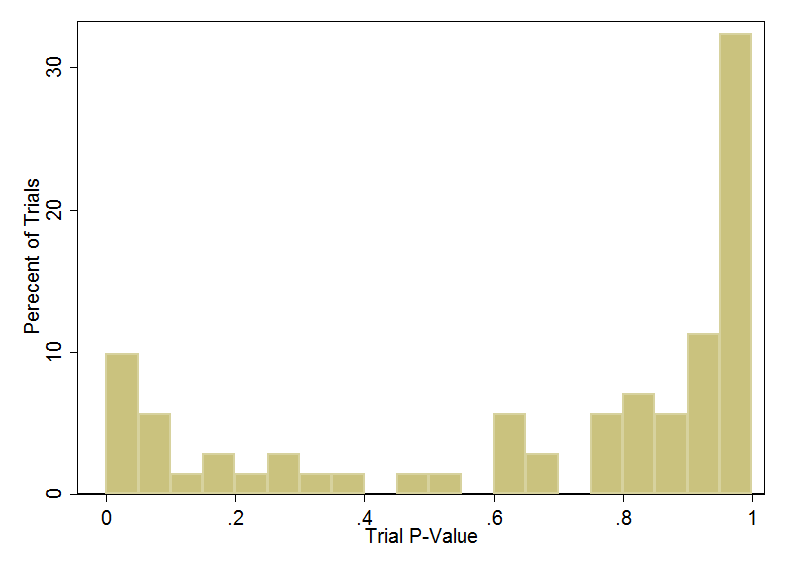
Yikes. A bunch of the retracted trials have baseline balance that is just too good to be true.
But let's take a step back. Why would an author do this?
Like, if I wanted to fake my data, why not just flip a few outcomes between the groups. Take a few deaths away from the intervention arm, add them to the placebo arm. The baseline data wouldn't change at all. I wish Carlisle had correlated his results to the study outcomes, but we don't have that data.
I think the implication is that maybe these patients were never enrolled in the first place. They are made up entirely. This, frankly, strikes me as really implausible. Yes, there are some notable frauds out there where the data is entirely made up, but the risk of this is just so high. And the alternatives, if you are going to be unethical anyway, are frankly, much easier.
So what else could be going on?
Well, a lot of it seems to be simple errors in transcription of data. There are several examples in the paper, but for instance the single trial with the worst trial p-value score is the AASK trial, which randomized patients to one of two blood pressure targets and one of three medications:
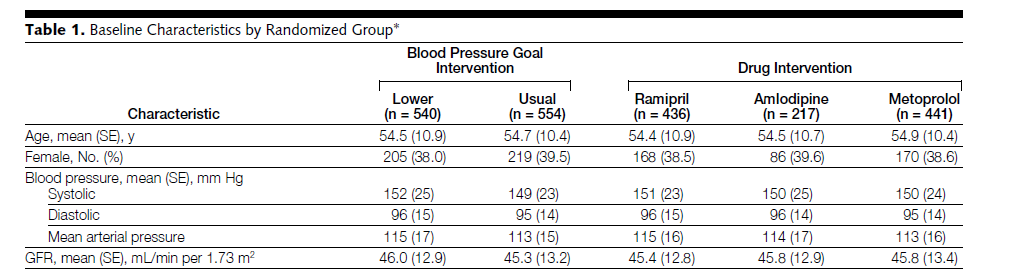
The problem in Table 1 here are those little SE's in parentheses. That means standard error, but it's a typo. It's supposed to read SD for standard deviation. If we take the table at face-value, we'd find that these groups are FAR too balanced to be realistic under true randomization.
When we assume the numbers are standard deviations, the study p-value goes all the way up to 0.90. Nothing to see here.
The second most suspiciously balanced study, appearing in the New England Journal of Medicine also seems to have made the standard-error, standard-deviation typo.
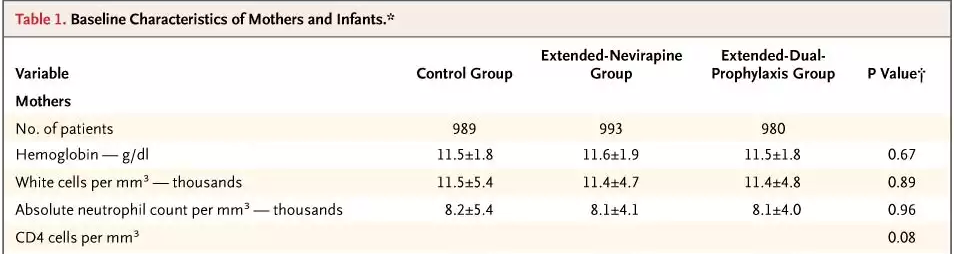
If you believe that the standard error for hemoglobin in a trial of 989 people is 1.8, that means the standard deviation is 56.6 g/dl – patently ridiculous. This may be sloppy, but it ain't fraud.
The third most suspiciously balanced study was subsequently retracted.
But there's another problem with Carlisle's method, beyond the fact that it is really good at identifying typos.
Remember when I said he used Stouffer's method to combine p-values? That only works if all the p-values are independent. But that is really never the case in medicine. Older people have higher cholesterol, on average, so if the age group got unbalanced due just to chance, so did the cholesterol group, yet combining them inflates the sense that something strange is going on.
I'll take it to the extreme to prove the point. Let's pretend we report height in inches and height in yards and height in centimeters between our two groups.
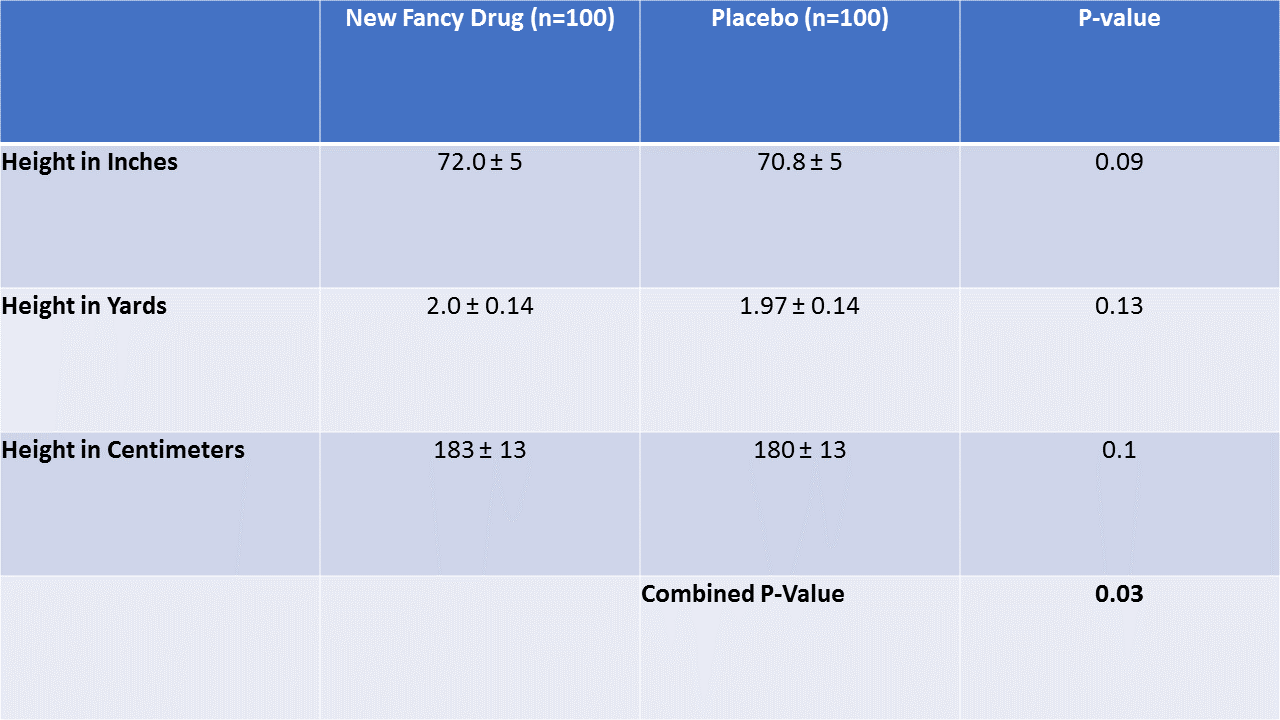
All three variables have p-values in the reasonable range. In fact, they only differ at all due to rounding. But the combined p-value is lower than any of the individual ones. This would be fair if height in inches and height in yards and height in centimeters weren't correlated – we'd want to identify a trial that had a lot of balance problems across many variables. But that isn't the case here. The three variables are perfectly correlated, and combining them gives extra weight to the same benign phenomenon.
With that in mind, what Carlisle has here is a screening test, not a diagnostic test. And it’s not a great screening test at that. His criteria would catch 15% of papers that were retracted, but that means that 85% slipped through the cracks. Meanwhile, this dragnet is sweeping up a bunch of papers where sleep-deprived medical residents made a transcription error when copying values into excel.
So is clinical trial fraud rampant? I don't really think so. This technique feels a bit like anomaly hunting – the same sort of thing we might see in a voter fraud analysis where people point to unusual data and then jump to unsustainable conclusions.
What the Carlisle method can be used for, though, is a quick screen at the level of the medical journal to ensure that the all-important table 1 was properly transcribed, and to, in some instances, ask a few pointed questions of the authors.